 |
Služba World-Wide Web je postavena na třech základních technologiích -- HTML, URL a HTTP. HTML je značkovací jazyk, který slouží k standardnímu popisu obsahu a struktury webovských stránek. URL je speciální druh adres používaných na Webu -- každá webovská stránka má svoji jednoznačnou adresu právě v podobě URL. HTTP -- Hypertext Transfer Protocol -- je protokol používaný při komunikaci mezi prohlížeči a webovskými servery. Pomocí tohoto protokolu se k serveru přenáší URL stránky, kterou uživatel (přes svůj prohlížeč) požaduje, a naopak server pomocí protokolu HTTP odesílá uživateli zpět stránku zapsanou v HTML.
Pro správné pochopení principů CGI-skriptů je nezbytná alespoň základní znalost protokolu HTTP. Proto se v dnešním pokračování seriálu podíváme na základní vlastnosti protokolu HTTP.
Protokol HTTP vychází z architektury klient/server. Klient -- v našem případě prohlížeč -- se spojí se serverem a pošle mu požadavek. Server jako reakci na klientův požadavek zasílá odpověď. Přesný formát požadavku a odpovědi je definován ve specifikaci protokolu HTTP. Celou situaci mírně komplikuje to, že dnes existují tři verze protokolu -- 0.9, 1.0 a 1.1. Formát požadavku a odpovědi se v jednotlivých verzích odlišuje.
|
GET uvedena cesta k požadovanému
dokumentu. Pokud chceme pomocí HTTP/0.9 získat například dokument
http://www.server.cz/~krystof/linky.html, musíme se
připojit k počítači www.server.cz na port 80 (standardní
port služby WWW) a zaslat požadavek:
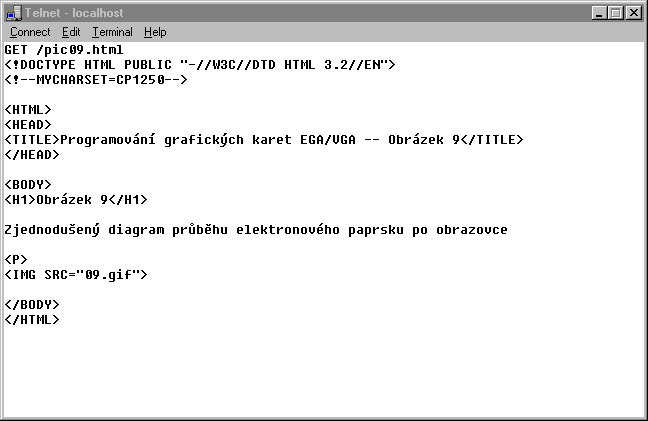
GET /~krystof/linky.htmlJako odpověď nám přijde obsah souboru
linky.html. Vše si
můžeme sami vyzkoušet a zahrát si na prohlížeč. Stačí spustit telnet a
přihlásit se k nějakému serveru na port 80. Pak napíšeme HTTP požadavek
a necháme se překvapit, co nám server odešle zpět (viz obr. 2).
 |
Na tomto místě musíme připomenout, že cesta za slovem
GET nemůže být prázdná a musí vždy obsahovat alespoň
lomítko:
GET /Možná vás napadlo, jaký dokument odešle server jako odpověď, pokud v požadavku není určen přímo soubor, ale pouze adresář (nebo dokonce jen kořenový adresář jako v našem příkladě). V tomto případě WWW-server hledá v adresáři soubor, který se jmenuje
index.html,
default.html či welcome.html -- záleží na
konfiguraci. Pokud jej nalezne, odešle jej jako odpověď. Pokud takový
soubor neexistuje, odešle výpis obsahu adresáře (pokud to není v
konfiguraci serveru zakázáno).
Jména souborů, které se hledají v případě požadavku, který obsahuje
pouze jméno adresáře, lze pro server Apache nastavit v konfiguračním
souboru srm.conf pomocí direktivy
DirectoryIndex. Díky této vlastnosti můžeme používat URL
adresy tvaru http://www.server.cz/.
metoda cesta_k_dokumentu HTTP/1.0 hlavičky prázdná_řádkaNejpoužívanější metodou je GET -- ta slouží k získání daného dokumentu ze serveru. Další dvě metody, které můžeme použít, jsou HEAD a POST. První z nich zašle pouze hlavičky, které obsahují různé metainformace o dokumentu -- např. datum poslední modifikace apod. Metoda POST slouží k odeslání dat z formuláře na server. V tomto případě za prázdnou řádkou obsahuje požadavek ještě hodnoty jednotlivých polí formuláře.
Hlavičky slouží pro přenos různých doplňujících informací. Každá
hlavička je na samostatné řádce a má tvar
jméno_hlavičky: hodnota. Význam
jednotlivých hlaviček popíšeme později. Jejich použití je nepovinné a
proto nejjednodušší požadavek v HTTP/1.0 vypadá takto:
GET /~krystof/linky.html HTTP/1.0 prázdná_řádkaOdpověď má v HTTP/1.0 také odlišný formát. Nesestává pouze ze samotného obsahu zasílané stránky, ale obsahuje i mnoho důležitých a užitečných informací.
HTTP/1.0 stavový_kód stavové_hlášení hlavičky prázdná_řádka obsah_odpovědiStavový kód je třímístné číslo, které indikuje, jak se povedlo uspokojit požadavek. Přehled stavových kódů je uveden v tabulce 1.
Stavové hlášení je slovní popis stavového kódu, který je pro člověka přeci jen srozumitelnější. Pokud vše proběhlo v pořádku, měla by první řádka odpovědi vypadat následovně
HTTP/1.0 200 OKPřehled stavových kódů a hlášení je v tabulce 1.
| Kód | Popis |
|---|---|
| 1xx -- Informační kódy (nepoužívá se) | |
| 2xx -- Úspěšné vyřízení požadavku | |
| 200 OK | Požadavek byl úspěšně zpracován |
| 201 Created | Výsledkem požadavku je nově vytvořený objekt |
| 200 Accepted | Požadavek byl přijat, ale dosud není zpracován |
| 200 No content | Požadavek byl úspěšně zpracován, ale jeho výsledkem nejsou žádná data pro klienta |
| 3xx -- Přesměrování | |
| 301 Moved Permanently | Požadovaný objekt byl trvale přemístěn na jinou adresu |
| 302 Moved Temporarily | Požadovaný objekt byl dočasně přemístěn na jinou adresu |
| 304 Not Modified | Objekt nebyl změněn (odpověď při podmíněném
požadavku pomocí hlavičky If-Modified-
Since)
|
| 4xx -- Chyba klienta | |
| 400 Bad Request | Špatná syntaxe dotazu |
| 401 Unauthorized | Objekt je dostupný pouze po autorizaci |
| 403 Forbidden | Požadavek je v pořádku, ale server nemá povoleno jej vykonat |
| 404 Not Found | Požadovaný objekt nebyl na serveru nalezen |
| 5xx -- Chyba na straně serveru | |
| 500 Internal Server Error | Serveru se něco stalo a nemůže vyplnit požadavek |
| 501 Not Implemented | Server nepodporuje metodu uvedenou v požadavku |
| 502 Bad Gateway | Server, pracující jako gateway, dostal špatnou odpověď od dalšího serveru |
| 503 Service Unavailable | Služba je nedostupná (přetížení, údržba serveru) |
Předchozí verze protokolu HTTP vytvářely pro každý objekt nové
spojení a poté jej pomocí HTTP přenesly. Pokud tedy např. HTML stránka
obsahovala čtyři obrázky, pro její stažení bylo potřeba navázat 5
spojení (1 stránka + 4 obrázky). Navázání spojení je však náročné jak na
čas, tak na přenosovou kapacitu sítě. HTTP/1.1 proto spojení mezi
klientem a serverem po vyřízení požadavku neuzavírá, ale umožňuje jej
použít pro přenos více objektů. Tím dochází k ušetření času potřebného
k přenosu webovských stránek. Spojení může ukončit klient nebo server
tím, že do požadavku/odpovědi zařadí hlavičku Connection:
close.
V každém požadavku, který vyhovuje standardu HTTP/1.1, musíme použít
hlavičku Host. Jako hodnota se uvádí doménové jméno
serveru, ze kterého požadujeme stránku. Nejjednodušší požadavek pak
vypadá takto
GET /~krystof/linky.html HTTP/1.1 Host: www.server.cz prázdná_řádkaPoužití této hlavičky je povinné kvůli virtuálním serverům. Dnes je na Internetu běžné, že poskytovatelé připojení umožňují na svých serverech vystavovat stránky svým zákazníkům. Jako službu nabízejí i umístění stránek na adrese typu
http://www.firma.cz místo
obvyklého http://www.poskytovatel.cz/firma. Samozřejmě, že
poskytovatel na jednom serveru (počítači) vystavuje stránky několika
firem. Problém je však v tom, že server má obvykle jen jednu IP-adresu,
ke které se připojují klienti. Prohlížeč se tedy připojí k serveru na
port 80 a v požadavku HTTP/1.0 pošle pouze cestu k dokumentu. Server
nemá šanci zjistit, z kterého virtuálního serveru je dokument požadován.
Tato situace se řešila přiřazením několika IP-adres jednomu počítači.
Pro každý virtuální server musela existovat jedinečná IP-adresa. V tomto
případě již server podle IP-rozhraní, ke kterému se prohlížeč připojil,
mohl určit virtuální server, na který požadavek směřuje.
Toto ne příliš elegantní řešení zbytečně plýtvalo IP-adresami a kladlo zvýšené požadavky na konfiguraci serveru při přidání nového virtuálního serveru. Tím, že požadavky HTTP/1.1 obsahují jméno serveru, odpadá potřeba zřizování nové IP-adresy pro každý virtuální server. Na jedné IP-adrese nyní může být přístupný neomezený počet virtuálních serverů. Jediným háčkem jistě elegantního řešení problému je fakt, že starší prohlížeče nepodporují HTTP/1.1.
HTTP/1.1 přidává i několik nových metod požadavků. Pro potřeby pohodlného publikování na Webu jsou to především metody PUT a DELETE. První z nich slouží k uložení zaslaného objektu (nejčastěji HTML stránky) na dané URL. HTML-editor tak může přímo na WWW-server uložit nově vytvořenou nebo modifikovanou stránku, aniž by se o to musel snažit uživatel sám například pomocí FTP. Metoda DELETE slouží k odstranění stránky ze serveru. Další metody TRACE, CONNECT a OPTIONS slouží k zjišťování, analyzování a nastavení způsobu spojení.
text/html, pro obyčejný
text text/plain, obrázky mají podle použitého formátu jeden
z typů image/gif, image/jpeg nebo
image/png. Podle typu dat prohlížeč pozná, jak příchozí
data interpretovat. HTML stránka zasílaná prohlížeči jako odpověď, proto
mezi hlavičkami obsahuje následující řádku
Content-Type: text/html
Location ukazuje. Jako adresu je potřeba uvést úplné
absolutní URL. Např.
Location: http://manes.vse.cz/~xkosj06/index.html
If-Modified-Since: Mon, 30 Mar 1998 12:00:00 GMT
User-Agent posílá prohlížeč svoji identifikaci
-- obvykle své jméno, číslo verze a platformu, na které je spuštěn.
Server naopak obsahuje identifikaci serveru, který vyřídil
požadavek. Př.:
User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows NT) Server: Apache/1.3b3